
大規模言語モデル(LLM)の性能を最大限に引き出すために、プロンプティング技術は非常に重要です。
特に、Chain-of-Thought(CoT)プロンプティングやZero-Shot Chain-of-Thought(Zero-Shot CoT)、自己整合性(Self-Consistency)付きChain-of-Thought(CoT-SC)、さらにはTree of Thoughts(ToT)のような技術は、複雑なタスクに対するモデルの推論能力を大幅に向上させます。
この記事では、これらの高度なプロンプティング技術について説明し、それらがどのようにLLMの精度向上に寄与するかを探っていきます。
また、Few-Shotプロンプティングとの使い分けや、CoTと他の手法との比較についても詳しく解説します。
Chain-of-Thoughtプロンプティングの基礎
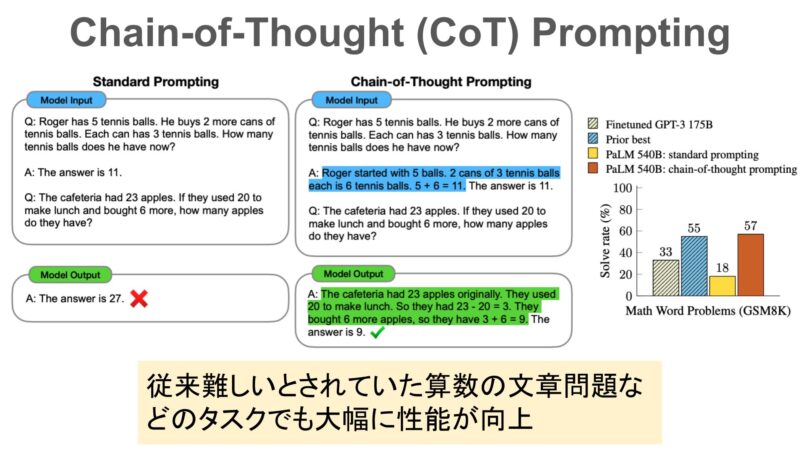
Chain-of-Thought(CoT)プロンプティングは、モデルが複雑な推論を行う際に、その思考過程を明示的に示す手法です。
CoTプロンプティングを用いることで、モデルはただ単に答えを出すのではなく、問題を解くプロセスを段階的に示すことができます。
CoTの仕組み

従来のプロンプティングでは、モデルは一度の推論で答えを導きますが、CoTでは複数のステップに分けて問題を解きます。この手法は、特に数学や論理的な推論に強みを発揮します。
CoTプロンプティングでは、途中の思考過程が明確化されるため、複数ステップを要する問題に対して信頼性の高い応答が期待できます。
CoTの利点
- ステップバイステップの思考:CoTでは、モデルが単一の回答を返すのではなく、その過程を追うことで、間違いや推論エラーが減少します。
- 複雑なタスクに強い:多段階推論が必要な問題に適しており、数学の問題や論理的な課題に特に有効です。
- モデルの透明性:CoTでは思考過程が明示されるため、モデルの判断がどのように行われたのかを確認でき、信頼性が高まります。
Few-ShotプロンプティングとCoTの使い分け

Chain-of-Thoughtプロンプティングと似た技術にFew-Shotプロンプティングがありますが、それぞれ異なる状況で有効に機能します。
Few-Shotプロンプティングは、モデルにいくつかの事例を提示し、それに基づいた推論を行わせます。
一方、Chain-of-Thoughtプロンプティングは、複雑な問題に対して、モデルが思考過程をステップバイステップで明示しながら解答を導く手法です。
使い分けのポイント
- シンプルなタスク:Few-Shotプロンプティングは、比較的シンプルな質問応答や分類タスクに有効です。いくつかの事例を提供することで、モデルがそのパターンを学習し、応答を生成します。
- 複雑な推論タスク:CoTプロンプティングは、複数のステップが必要な問題に向いています。例えば、数学の文章問題や、複雑な論理的推論のタスクに対しては、思考の過程を明示することで、より正確な答えに導きます。
Few-Shotプロンプティングは、シンプルな質問に対応しやすく、CoTはより多段階の問題に対して有効な手法と言えるでしょう。
Zero-Shot Chain-of-Thought

Chain-of-Thoughtの手法の一つにZero-Shot Chain-of-Thought(Zero-Shot CoT)という手法があります。
Zero-Shot CoTは、事例や前提条件を与えず、モデルにステップバイステップの推論を促す手法です。
この技術は、モデルに「Let’s think step by step.(段階的に考えてみましょう)」といったフレーズを追加することで、推論過程を自発的に構築させ、複雑な問題にも対応できるようにします。
従来のZero-Shotプロンプティングは、単純な質問応答に適していましたが、Zero-Shot CoTを用いることで、モデルが内部で論理的プロセスを組み立て、より複雑な問題に対しても正確な解答を導き出すことができます。
この手法により、モデルは単なる知識の提供にとどまらず、複数の思考ステップを自動的に踏むようになります。
Zero-Shot CoTの手法

Zero-Shot CoTでは、モデルに具体的な事例を与えることなく、思考プロセスをステップごとに進めるような「Let’s think step by step.(段階的に考えてみましょう)」といったプロンプトを入力します。
これにより、モデルは複数の段階を経て推論を行うことができ、複雑なタスクや論理推論の精度が向上します。
Zero-Shot CoTのメリット
- 前提条件が不要: モデルに事例を提示することなく、推論を自発的にステップバイステップで行わせるため、シンプルなプロンプトであっても複雑な問題を解決できます。
- 広範な適用可能性: 数学の問題や論理的推論など、推論過程が重要なタスクに特に有効です。ゼロショット設定で、複雑な推論を要するタスクにも対応できるため、柔軟に利用できます。
Zero-Shot CoTは、モデルが自発的に思考過程を構築する点で従来のゼロショットプロンプティングと異なり、複雑な問題に対しても高い精度で対応できる革新的な手法です。
自己整合性(Self-Consistency)による推論の向上
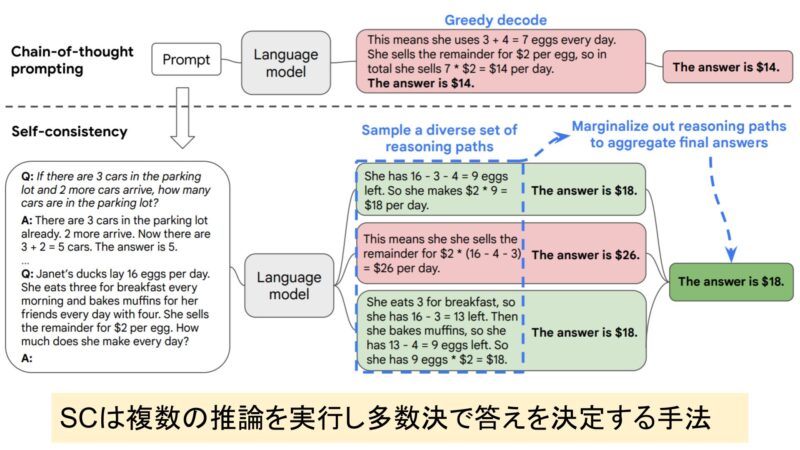
自己整合性(Self-Consistency)は、LLMが複数の推論を行い、その中から最も一貫性のある答えを選ぶ手法です。
これにより、単一の推論に頼らず、モデルが正確で信頼性の高い解答を導き出します。特に、複雑な問題や多段階の推論が必要な場面で効果を発揮します。
従来のChain-of-Thought(CoT)プロンプティングでは、モデルがステップバイステップで推論過程を明示しながら進行しますが、1回限りの推論では誤った仮定や計算ミスが結果に影響を与える可能性があります。
自己整合性を取り入れることで、モデルが同じ質問に対して複数回の推論を行い、最も多く現れる正しい答えを選択することで、推論の安定性が向上します。
自己整合性の手法
自己整合性では、複数回の推論を通じて最も頻出する答えを選び出します。これにより、たとえ1回の推論で誤りが発生した場合でも、他の正しい推論結果を基に最終的な正解を得ることができます。
自己整合性とCoTの組み合わせ
自己整合性は特にChain-of-Thought(CoT)プロンプティングと組み合わせることで、より強力な結果を生み出します。
CoTでは、モデルが逐次的に推論を行いますが、推論過程に誤りがあった場合、その結果が解答に影響するリスクがあります。
そこで自己整合性を適用し、同じCoTプロンプトを複数回実行することで、最も一貫性のある推論過程を選び出し、信頼性をさらに高めることが可能です。
このアプローチは、特に複雑で長い推論が必要なタスクや、異なる解答が得られる可能性のあるタスクにおいて、正確さと安定性を向上させるのに有効な手法となります。
Tree of Thoughts(ToT)
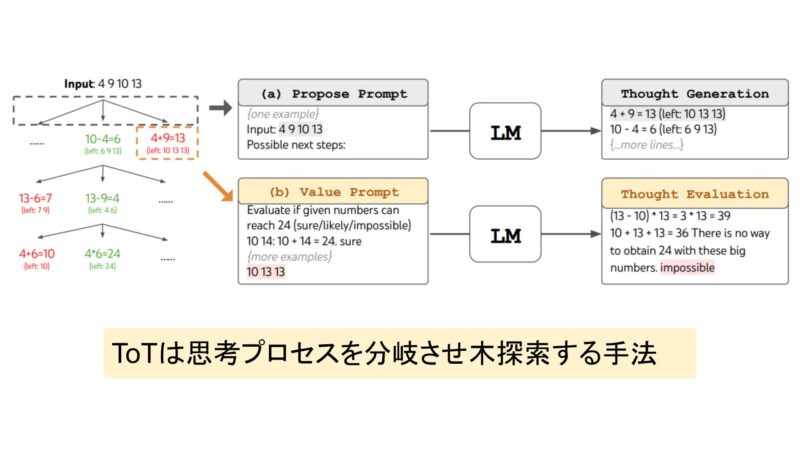
Tree of Thoughts(ToT)は、LLMが複数の思考プロセスを分岐させ、各思考の結果を評価する手法です。
従来のCoTや自己整合性では、一連の直線的な推論が行われますが、ToTでは異なる思考の流れが同時に進行し、それぞれの流れに基づいて最適な解答が選ばれます。
ToTの方法
ToTは、問題に対して複数の解決方法を探索し、最終的に最も効果的な解決策を選びます。これは、探索木(ツリー)のように異なるルートを同時に進行させ、それぞれの思考過程を評価することで実現されます。
ToTでは、探索範囲が広がることで、より戦略的な思考が必要なタスクに有効です。
CoT、CoT-SC、Zero-Shot CoT、ToTの比較
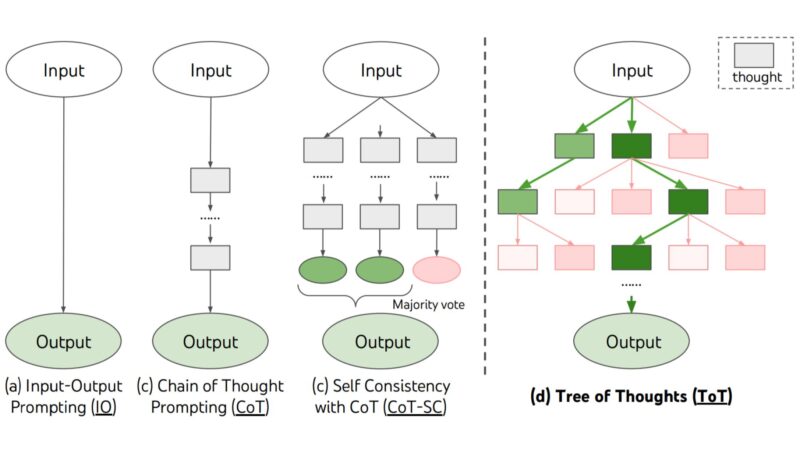
Chain-of-Thought(CoT)、Self-Consistency with Chain-of-Thought(CoT-SC)、Zero-Shot Chain-of-Thought(Zero-Shot CoT)、そしてTree of Thoughts(ToT)は、それぞれ異なる方法でLLMの推論能力を引き出します。
これらの手法は、それぞれの強みを活かして、さまざまなタスクに適用されます。
各手法の特徴
- CoT(Chain-of-Thought)
モデルが逐次的に思考過程を明示するため、複数ステップを必要とするタスクでの推論能力が向上します。特に、解答の正当性を確認したいタスクで有効です。 - Zero-Shot CoT(Zero-Shot Chain-of-Thought)
モデルが前提条件や事例を持たずに自らステップバイステップの推論過程を生成します。ゼロショット設定でも高い推論能力を発揮し、事例の準備が難しいタスクに適用できます。 - CoT-SC(Self-Consistency with Chain-of-Thought)
モデルが複数の異なる推論を行い、その中から最も多くの支持を得た推論結果を選択するため、答えの一貫性が向上します。特に複雑で、答えが多様な可能性を持つタスクに適しています。 - ToT(Tree of Thoughts)
複数の思考パターンを同時に探索し、それぞれを評価することで最適な解答を選びます。特に、複数の解決策が存在する問題において、最も効果的な答えを選択できる強力な手法です。
以下の表は、これらの手法の違いを比較したものです。
| 手法 | 特徴 | 適用タスク |
| CoT | ステップバイステップの推論を行い、各ステップの過程を明示する | 複雑な算数問題、論理推論、推論プロセスの可視化が重要なタスク |
| Zero-Shot CoT | 事例なしに、モデルが自発的にステップバイステップで推論過程を構築する | 前提条件の少ない複雑な問題、ゼロショット推論 |
| CoT-SC | 複数の推論を行い、最も整合性のある答えを選択。安定性を向上させる | 複雑な推論タスク、信頼性が求められるタスク |
| ToT | 思考の分岐を探索し、各分岐を評価して最適な解答を選択する | 複数の解決方法があり、より高度な戦略的思考が必要なタスク |
まとめ
本記事では、Chain-of-Thoughtプロンプティング、Zero-Shot CoT、自己整合性、Tree of Thoughtsの技術を解説しました。
これらの手法は、大規模言語モデルが複雑なタスクを処理する際に不可欠なものであり、それぞれの技術が異なるタスクに対して有効に機能します。
今後のLLMの発展に伴い、これらの高度なプロンプティング技術はさらに洗練され、広範な応用が期待される技術です。
出典
- https://proceedings.neurips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html ↩︎
- https://proceedings.neurips.cc/paper_files/paper/2022/hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html ↩︎
- https://arxiv.org/abs/2203.11171 ↩︎
- https://arxiv.org/abs/2305.10601 ↩︎

