
大規模言語モデル(LLM)を効果的に利用するための、「プロンプティング(Prompting)」と「文脈内学習(In-Context Learning)」の理解を深めましょう。
プロンプティングは、モデルに指示を与え、タスクを解決するために必要な情報を引き出すための技術であり、文脈内学習は、追加の学習を行わずに与えられた文脈からモデルが学習する仕組みを指します。
本記事では、プロンプティングの基本的な概念と、文脈内学習の重要性について解説します。ゼロショット(Zero-Shot)やフューショット(Few-Shot)のプロンプティングの違い、効果的なプロンプト設計の方法、プロンプティングがLLMの性能に与える影響についても具体的に説明していきます。
プロンプティングとは何か
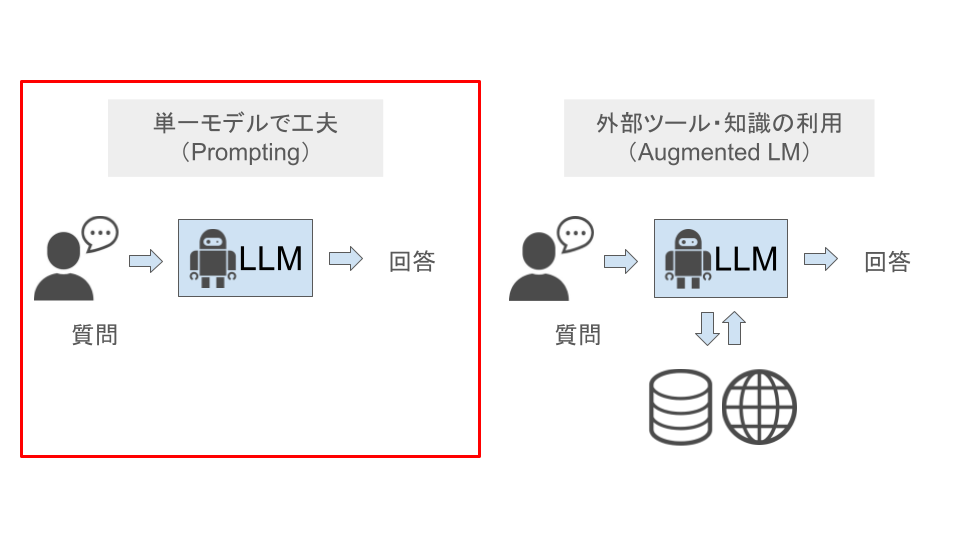
プロンプティング(Prompting)とは、言語モデルに対して特定の出力を引き出すための「指示文」を与える技術です。
LLMの追加学習を行うことなく、LLMに入力する指示文を工夫することで得たい回答を引き出す点が特徴です。
プロンプトは、簡単な質問形式や指示、あるいは問題解決のための詳細な文脈を含むことができます。LLMは、このプロンプトを基にして、その指示に最適な形で回答を生成します。

プロンプトの種類
プロンプトには主に以下の3種類があります。
- ゼロショットプロンプティング(Zero-Shot Prompting)
事前に例を提供することなく、モデルにタスクを実行させる方法です。この方式では、モデルが特定の知識に基づいて直接応答を生成します。 - ワンショットプロンプティング(One-Shot Prompting)
タスクを実行する前に、1つの例を提示してからモデルにタスクを実行させる方法です。この1つの例によって、モデルは応答を調整し、特定のパターンに基づいた出力を生成します。 - フューショットプロンプティング(Few-Shot Prompting)
タスクを実行する前に、いくつかの例をモデルに示すことで、より正確な結果を得る方法です。文脈や事例を提示することで、モデルがそのパターンを理解し、出力を調整します。
プロンプト設計の重要性
適切なプロンプト設計は、モデルの性能に直接影響します。
例えば、単に「日本の首都はどこですか?」と質問する場合と、「日本の首都は何ですか?歴史的背景に基づいて説明してください。」と質問する場合とでは、モデルの応答が大きく異なります。
効果的なプロンプトを作成するためには、次の点に留意する必要があります。
- 明確な質問形式: 指示が曖昧だと、モデルの出力も不正確になる可能性が高まります。できるだけ具体的な指示を与えることが重要です。
- 文脈提供: モデルがどのような情報に基づいて出力を生成するのかを明確にするために、適切な文脈を提供することが大切です。
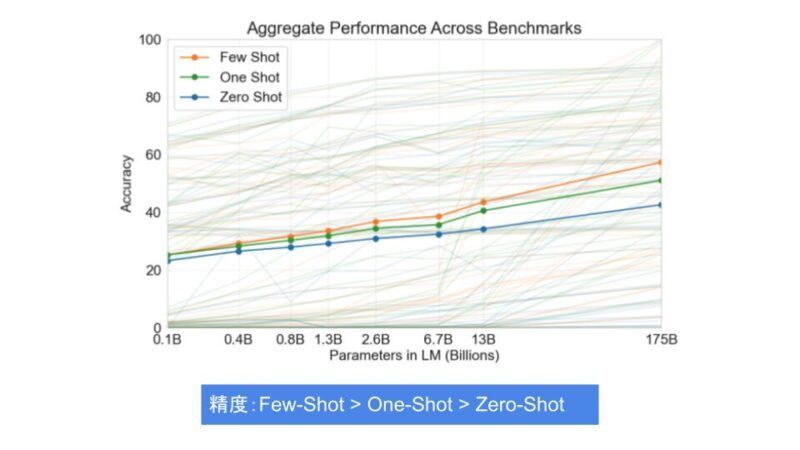
Zero-Shot、One-Shot、Few-Shotプロンプティングの違い

ゼロショットプロンプティング(Zero-Shot)、ワンショットプロンプティング(One-Shot)、フューショットプロンプティング(Few-Shot)の主な違いは、事前にモデルに示す例の数です。これにより、モデルの推論精度や応答の質が異なる結果を生むことがあります。
ゼロショットプロンプティング(Zero-Shot Prompting)

ゼロショットプロンプティングでは、モデルに一切の事例や例を示さずに、直接的に質問を投げかけます。これにより、モデルは過去に学習した知識やデータに基づいて推論(応答)を行います。
この方式は、簡単な質問や、一般的な知識に対して効果的ですが、より複雑なタスクや文脈に基づいた推論が必要な場合には限界があります。
ワンショットプロンプティング(One-Shot Prompting)

ワンショットプロンプティングでは、1つの事例や例をモデルに示してからタスクを実行させます。
この方式は、ゼロショットよりもモデルが例に基づいた応答を生成でき、フューショットほどの多くの例を必要としないため、シンプルかつ効果的な手法です。
ワンショットプロンプティングは、事前に1つの例を与えることで、モデルがそのパターンに基づいてより正確な結果を提供することが期待できます。
フューショットプロンプティング(Few-Shot Prompting)

一方、フューショットプロンプティングでは、事例をいくつか示すことで、モデルがその事例に基づいてより正確な出力を生成できるようにします。
特に複雑なタスクにおいては、フューショットプロンプティングが有効です。
フューショットプロンプティングは、与えられた文脈や事例に基づいて推論を行うため、より高度な問題に対しても正確な応答を期待できます。
文脈内学習の重要性
文脈内学習(In-Context Learning)は、LLMが追加の学習を行わずに、与えられた文脈を基にその場で推論を行う技術です。
この手法により、ファインチューニングを行わなくても、モデルは新しいタスクに柔軟に対応できるようになります。
Few-Shotプロンプティングと文脈内学習
Few-Shotプロンプティングは、文脈内学習の一形態と言えます。
プロンプト内でいくつかの事例を提示することで、モデルはその事例を文脈として理解し、適切な応答を生成するので、追加の学習を必要とせずに、新しいタスクに即座に対応可能となります。
文脈内学習とFine-Tuning
文脈内学習では、プロンプトに含まれる情報に基づいてモデルが即座に推論を行います。
従来のモデルでは、タスクごとにファインチューニング(Fine-Tuning)が必要でしたが、文脈内学習では、与えられたプロンプトから直接推論を行うため、再学習なしで複数のタスクに対応することが可能となります。
文脈内学習のメリット
- タスクの多様性への対応
文脈内学習を利用することで、追加のトレーニングを行わなくても、異なるタスクにモデルを適応させることができます。例えば、ニュース記事の分類、質問応答、文書生成など、異なるタイプのタスクでも、一貫して高い性能を発揮できます。 - 柔軟性の向上
文脈内学習は、与えられたタスクに応じて、即座に柔軟な応答を生成できるため、さまざまな分野での応用が期待されています。
| メリット | デメリット | |
| 文脈内学習 | ・すべてのタスクで単一のモデルを使える ・学習コストがかからない | ・Fine-Tuningほど性能が出にくい ・推論コストが高い |
| Fine-Tuning | ・性能が出やすい ・毎回事例を入力する必要がない(推論コストが低い) | ・タスクごとにモデルが異なる ・学習コストが高い |
効果的なプロンプト設計のポイント

プロンプト設計の質がモデルの出力に大きく影響を与えます。
以下の要点を押さえてプロンプトを設計することで、モデルの応答精度を向上させることができます。
1. 明確な指示
明確で具体的な指示を与えることが、モデルが正確な応答を生成するための基本となりす。
曖昧なプロンプトは誤解を招き、不正確な応答が返されることが多くなります。
例:説明タスク
- 悪いプロンプト:
- ◯◯について説明してください。
- 良いプロンプト:
- ◯◯の形状、色、使用方法を説明してください。
2. コンテキストの提供
文脈を提供することで、AIはより適切な情報を引き出すことができます。
フューショットプロンプティングでは、いくつかの具体例を含めることで、モデルがタスクをより正確に理解しやすくなります。
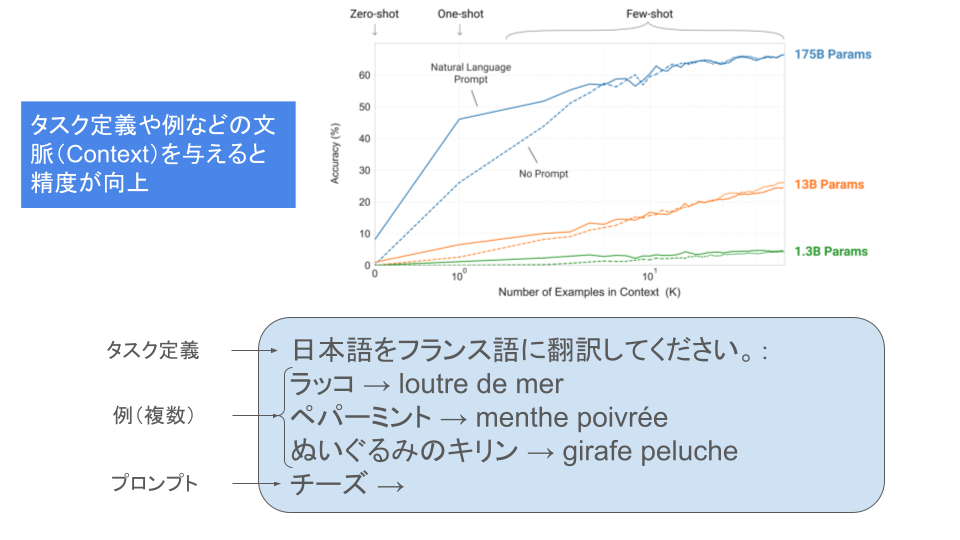
例:日本語からフランス語への翻訳タスク
- 悪いプロンプト:
- 日本語をフランス語に翻訳してください。:
チーズ →
- 日本語をフランス語に翻訳してください。:
- 良いプロンプト:
- 日本語をフランス語に翻訳してください。:
ラッコ → loutre de mer
ペパーミント → menthe poivrée
ぬいぐるみのキリン → girafe peluche
チーズ →
- 日本語をフランス語に翻訳してください。:
3. タスクの分解
複雑なタスクはステップごとに分割して提示することが推奨されます。これにより、モデルは逐次的にタスクを処理し、結果の正確さが向上します。
たとえば、長文の情報を要約する際には、「まず事実を抽出し、その後、検索クエリを生成して検証する」といった段階的な指示を与えることで、より信頼性の高い結果が得られます。
例:大量のテキストから要約を作成するタスク
- 悪いプロンプト:
- 5000文字の技術文書を要約してください。
- 良いプロンプト:
- ステップ1:事実の抽出 まず、長文の中から重要な事実を抽出します。
- 5000文字の技術文書の中から、主要な事実を5つに絞ってリストアップしてください。
- ステップ2:サブ要約の作成 次に、各事実を基にサブ要約を作成します。
- 事実に基づいて、それぞれ50文字以内で簡潔にまとめてください。
- ステップ3:検証と統合 最後に、各サブ要約を統合して、全体の要約を作成します。
- サブ要約を基に、全体の要約を100文字以内で作成してください。
- ステップ1:事実の抽出 まず、長文の中から重要な事実を抽出します。
4. 質問のフォーマット
質問形式のプロンプトを使用することで、モデルの応答が明確になりやすいです。
Chain-of-Thought(思考の連鎖)プロンプティングでは、AIモデルに複雑なタスクをステップごとに考えさせることで、推論能力を向上させ、より正確な応答を引き出すことができます。以下に具体例を示します。
例: 数学の問題を解く
元のタスク:「ナタリーは3つのリンゴを持っています。それを2人の友達と分け合う場合、1人あたり何個のリンゴを持つことになりますか?」
通常のプロンプトでは、AIは一度に答えを出すことになりますが、Chain-of-Thoughtプロンプティングではステップごとに考えさせることで、より確実な答えを得られます。
Chain-of-Thoughtプロンプトの例:
- 「まず、ナタリーが何個のリンゴを持っているか確認してください。」
- モデルの応答: 「ナタリーは3個のリンゴを持っています。」
- 「次に、リンゴを分け合う友達の数を確認してください。」
- モデルの応答: 「ナタリーには2人の友達がいます。」
- 「ナタリーを含めて、合計何人でリンゴを分けますか?」
- モデルの応答: 「ナタリーを含めて、合計3人です。」
- 「リンゴを3人で均等に分けると、1人あたり何個になりますか?」
- モデルの応答: 「1人あたり1個になります。」
このように、Chain-of-Thoughtプロンプティングを使うことで、ステップごとに問題を分解しながらモデルに考えさせ、複雑な問題でも誤りが少なくなります。この手法は、推論や論理的な思考が必要なタスクに特に有効です。
これらのテクニックを活用することで、プロンプティングの質を高め、AIの応答をより効果的にコントロールすることが可能となります。
プロンプティングがLLMの性能に与える影響
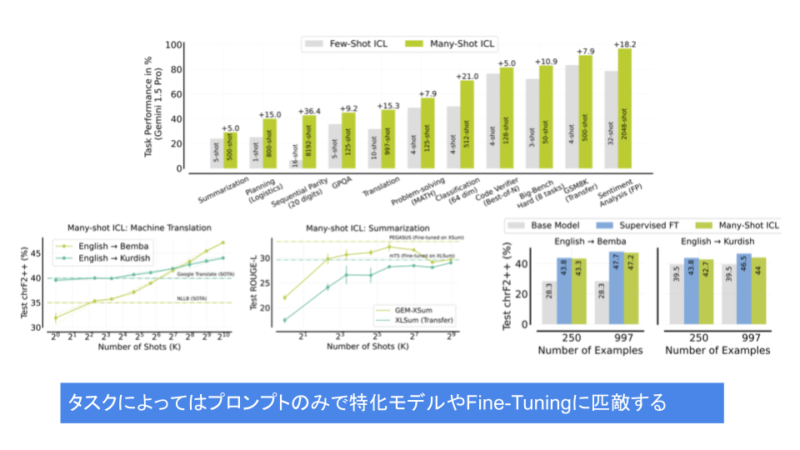
プロンプティングは、LLMの応答品質や推論精度に大きな影響を与えます。
プロンプトの設計が適切であれば、モデルはより正確で信頼性の高い結果を返しますが、逆に不適切なプロンプトでは誤った情報を生成する可能性が高まります。
適切なプロンプト設計によって、LLMは多様なタスクに柔軟に対応し、ユーザーが必要とする結果を効果的に提供することが可能となります。
プロンプティングと文脈内学習のまとめ
プロンプティングは、LLMを最大限に活用するための重要な技術です。
ゼロショットやフューショットプロンプティングの違いを理解し、文脈内学習を利用することで、LLMの追加学習を行わずに複雑なタスクに対応することが可能となります。
また、効果的なプロンプト設計がモデルの性能に与える影響を考慮し、適切な指示や文脈を提供することが、優れた結果を得るための鍵となります。
今後の技術進展に伴い、プロンプティングや文脈内学習の技術がさらに洗練され、より幅広い応用が期待されています。

